忍不住了,我想说,上个月买的 Lovart 会员,真的是太值了。
谁能想到,一个月后,我们真的做出了一条爆款短片。
昨天我同事,用 Lovart 模仿电影《浪浪山的小妖怪》的风格,做出了一个 30 秒的短片。
效果非常好,我感觉是时候用它来做一些有价值的短视频了。接下来,我打算单独补一个人,专攻 AI 视频方向。
八年前,我错过了抖音的红利期,眼睁睁看着一批人靠短视频起飞,这次,我不想再做旁观者了。AI 正在重塑内容创作的逻辑,用人话讲就是:AI 视频的红利期,正式开始了。
#01
一个全新的机会
最近,从 Google 的 Nano Banana,到字节的 Seedream 4.0,我们已经看到了图片生成模型的能力在疯狂跃迁,清晰度更高、细节更逼真、角色一致性更好、遵循指令的能力也更强。
如果说数码相机的出现,让摄影从专业技能变成了日常表达,把记录世界的权力交到了每个人手里。
那么今天,这些新一代图片生成模型的到来,正在让图片创作经历一场更大的范式转换。
它们像是一支支画笔,能让任何人在几分钟内,把脑海里的想法具象为可以触摸的画面。
过去做一张图,要经历手绘、美术、渲染、调色……
如今一句话就能完成,而且在清晰度、细节、风格控制力上,甚至已经超过不少专业团队的手工水准。
我觉得,这是我们从“会不会做”,真正转向“想做点什么”的拐点。可惜的是,很多人还没意识到。
不过,这也正是机会,等到所有人都意识到时,竞争就会白热化。
#02
好的工具
Lovart 原本是一款设计类的 Agent,但自从 Nano Banana 火了之后,我就不再只把它当设计工具来用,而是把它当成一整套图片与视频的创作工作台。
我们团队最常用的是它的画布功能,画布里集成了不同的模型,模型就像画笔:
图片生成模型 Nano Banana 是画笔,字节的 Seedream 也是画笔;视频生成模型 Veo3 是画笔,可灵也是画笔。
在这块画布中,我可以像挑选画笔一样自由切换模型,根据创作需要选择最合适的工具,而不用在不同平台之间来回奔波。
切换一个新平台,意味着要重新注册账号、重新熟悉功能、重新搭建工作流。
而在 Lovart 里,我可以直接把所有精力都放在创作本身。不再被工具牵着走,而是让工具为创意服务。
我一直以来的判断是,图片模型的成熟,其实是为视频生成铺路的。现在大家都在说“文生图的时代来了”,但我总觉得,这不是终点,只是起点。
毕竟这个时代,主流的媒介是视频。
只要有足够好的图片模型出来,视频的生成水准也会随之上一个大台阶。
我一个导演朋友,主做动画类的内容,他说他们公司 AI 使用率已经相当高了。
我们公司曾经集体看过《浪浪山的小妖怪》这部电影,剧情动人,画面也很美,让人意外地产生共鸣。
我们这个小团伙,其实没人是名校出身,家里也没矿,这些年一路摸爬滚打下来,才慢慢明白,自己的人生剧本不是孙悟空。
很多创业者的目标是成为下一个张一鸣、王兴、刘强东,而我不是。
我自始至终就觉得,能把团队的小伙伴养活了,让大家能过上好日子,这就足够了。
我们,都是浪浪山的小妖怪。
所以这次创作,我们选取了电影里的一处真实场景为原型,尝试在 Lovart 上延伸出一套属于我们自己的故事。
#03
我们的创作
下面是具体的创作过程。
之前我写过,怎么在 Lovart 里用 Nano Banana 搭配可灵做视频,这次的流程其实差不多,只是把主要的图片模型换成了字节的 Seedream。
我们团队的感觉是,在漫画风格的画面上,Seedream 的表现远超 Nano Banana。
当然,也不是每次都一帆风顺。偶尔 Seedream 出图不理想,我们也会立刻切回 Nano Banana 重新跑一版。Lovart 最大的好处就在这里,它集成了不同的模型,也不会丢掉上下文。
咱们开始。打开 Lovart 网站:
https://www.lovart.ai
新建项目后,点击画布左侧的黑色「+」按钮,选择「Image Generator」图像生成器,就能挑选需要的模型了。模型就是画笔。相比 Nano Banana,Seedream 可以选择图片的比例,这个不错。下图都是 Lovart 中的截图。
接下来,我们找到电影中寺庙的真实图片,并附上电影的画面,请 Lovart 为我生成一张全新的照片。我的提示词如下:
参考左图,生成一座中国传统寺庙的二次元动漫风格插画,仅保留单层结构。寺庙上的文字必须与参考图一致,并保持清晰,同时带有自然破损痕迹,其余部分完全自由发挥,不必与参考图相同。墙面与柱子自然破旧,比例协调,不穿帮。前景去掉所有遮挡寺庙的元素,去掉寺庙上的牌匾,画面保持完全通透清晰。地面砖面参考乡下破瓦房风格,呈现严重自然破损,裂纹、磨损、风化痕迹明显且符合真实破坏逻辑。寺庙屋顶参考右图,并借鉴乡下破瓦房的风格,呈现真实自然破损效果,裂纹、斑驳、风化与褪色合理且符合建筑破坏逻辑,不显叠加或分层感。整体采用二次元清晰线条、赛璐璐上色、柔和低饱和色彩,呈现古朴沉稳的氛围。天空柔和动漫蓝,树木低饱和二次元风格,细节丰富,营造独特的二次元破旧美感。
注意,左图是实景图,右图是电影中的参考图,生成过程如下:

当然,也不是一次就能成功,AI 生图,还是免不了需要抽卡。这个大家需要耐心,或者有时候效果不好,就调调提示词。大致的工作逻辑就是这样。
寺庙的漫画图片出来之后,我的构思是,让人走到寺庙的空间中去。这时候,需要一个漫画人物。我之前曾经生成过一张半身照,但半身照肯定不够,这里,我恰好测试下模型能否给我扩成全身照。
如下 Gif 图,效果很好啊:
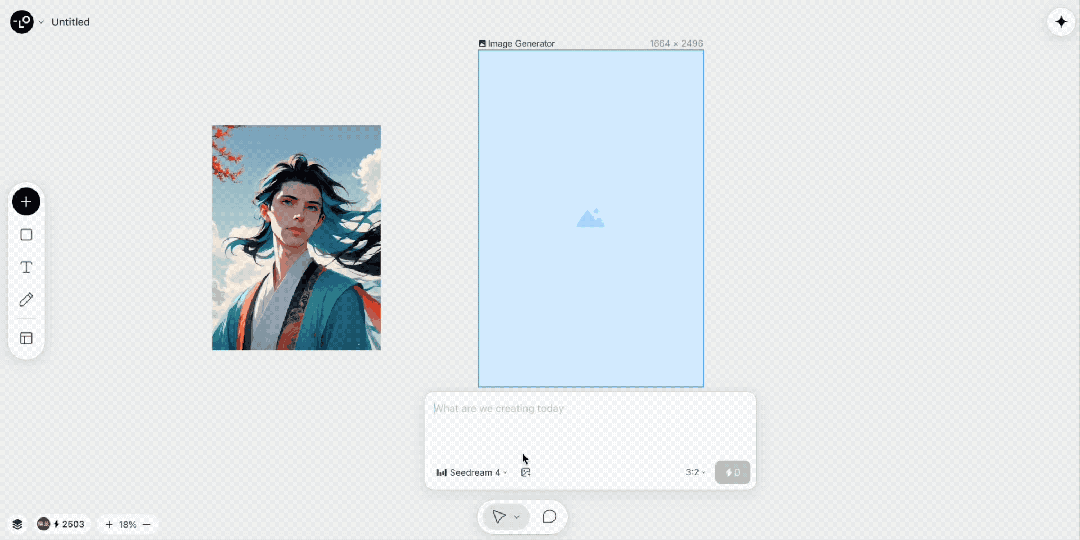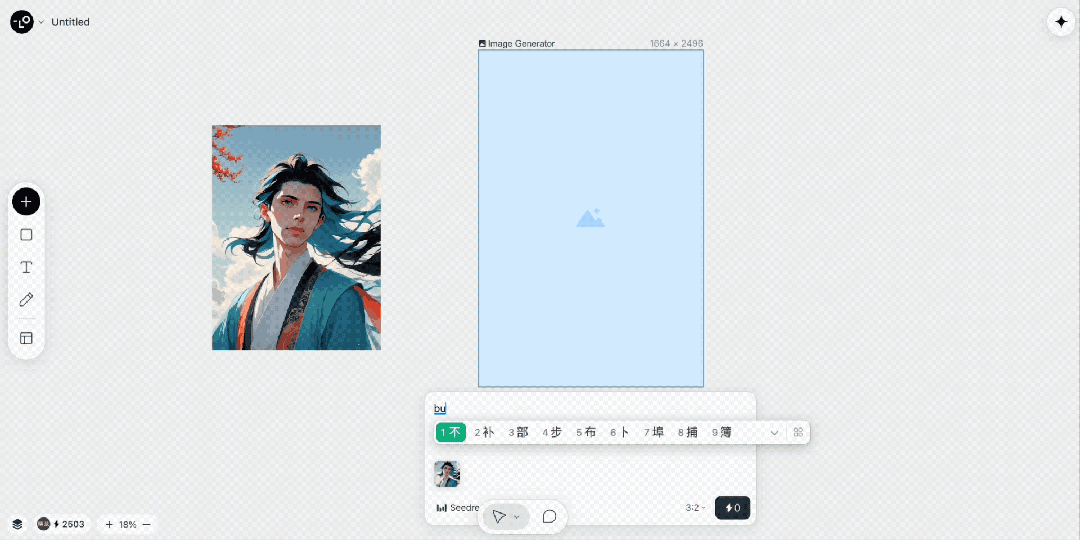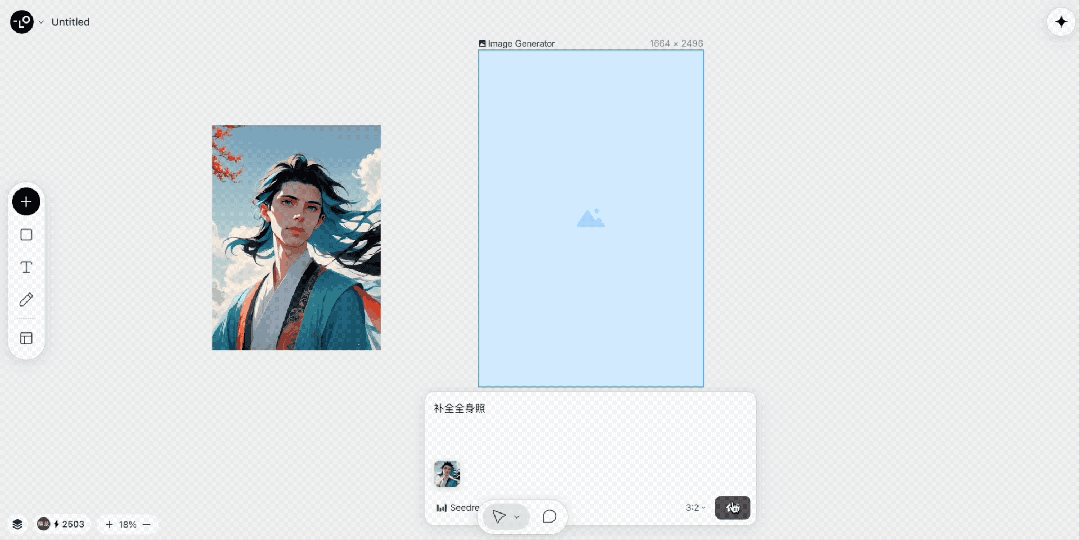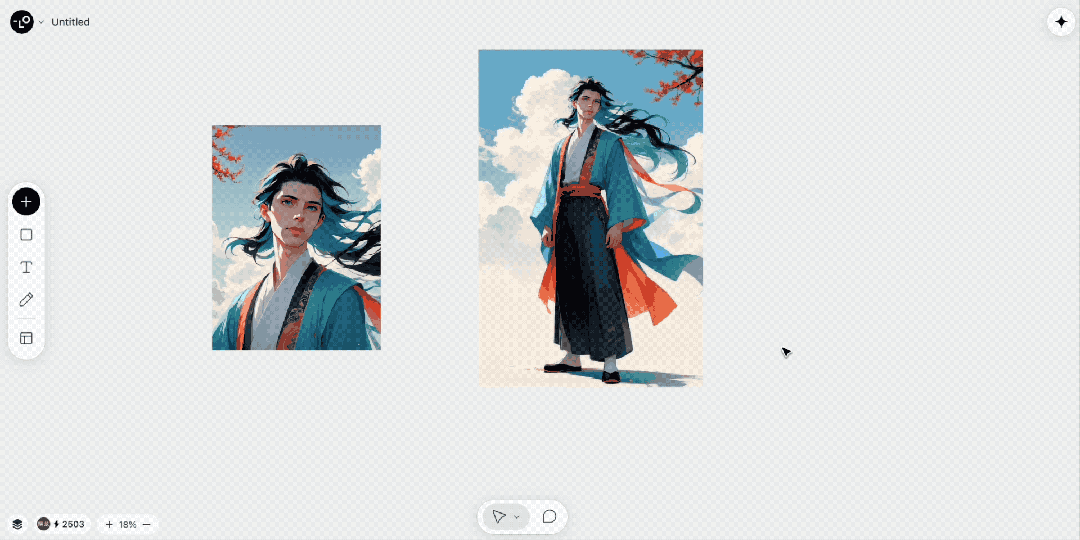
接着,我们再生成一张背影图。完美,大家看我的提示词是背面图,因为说背影似乎 AI get 不到。
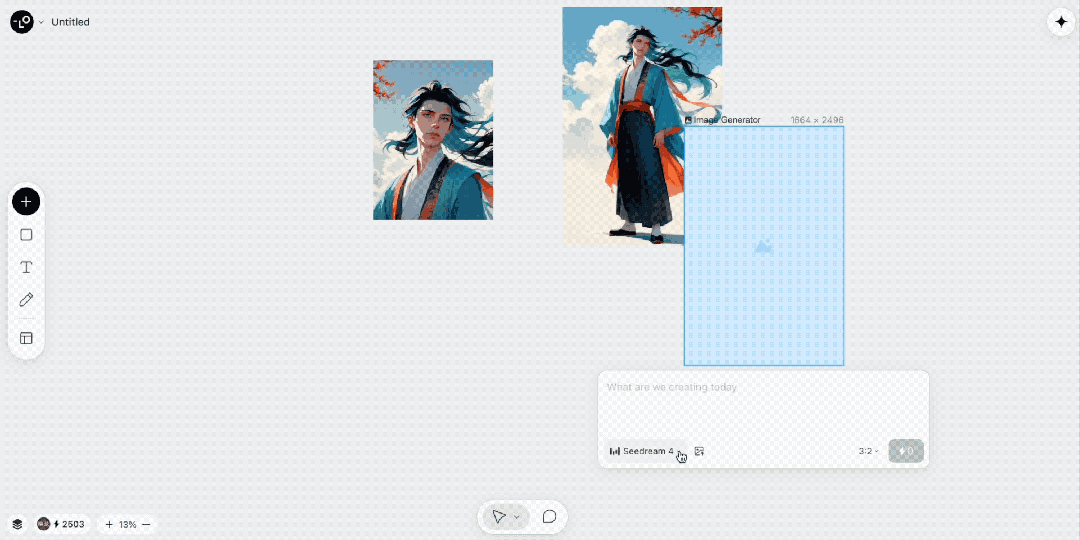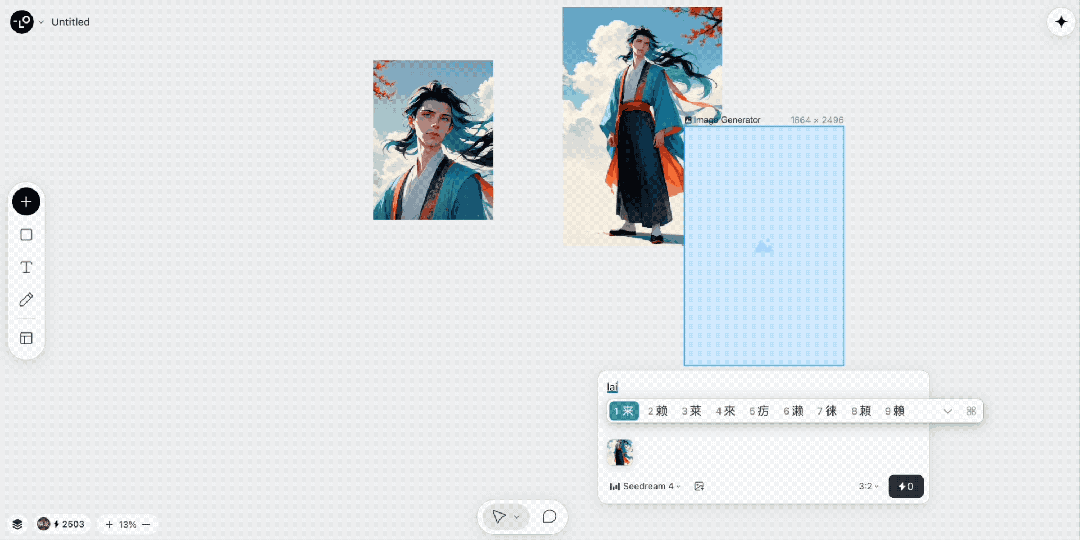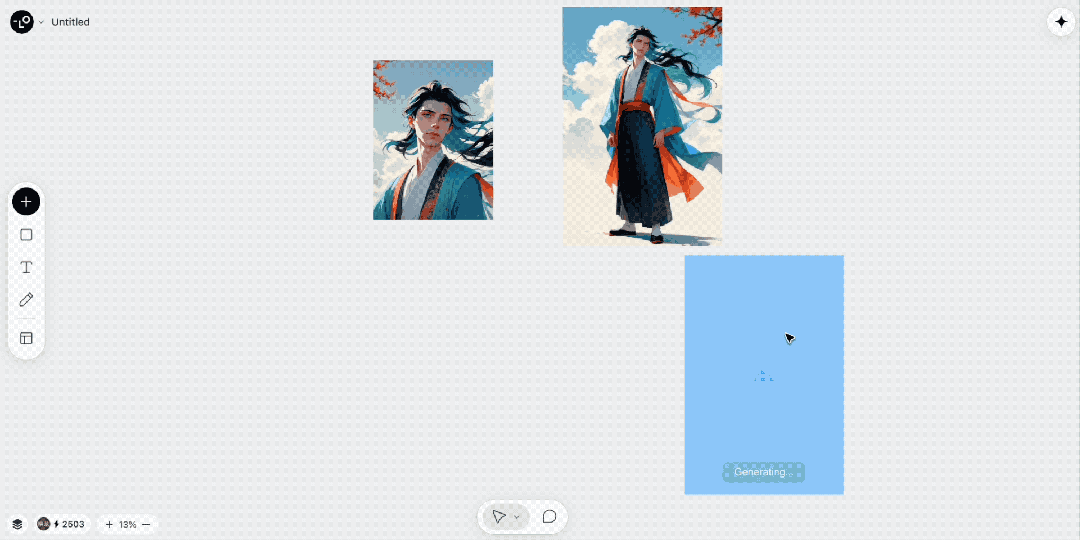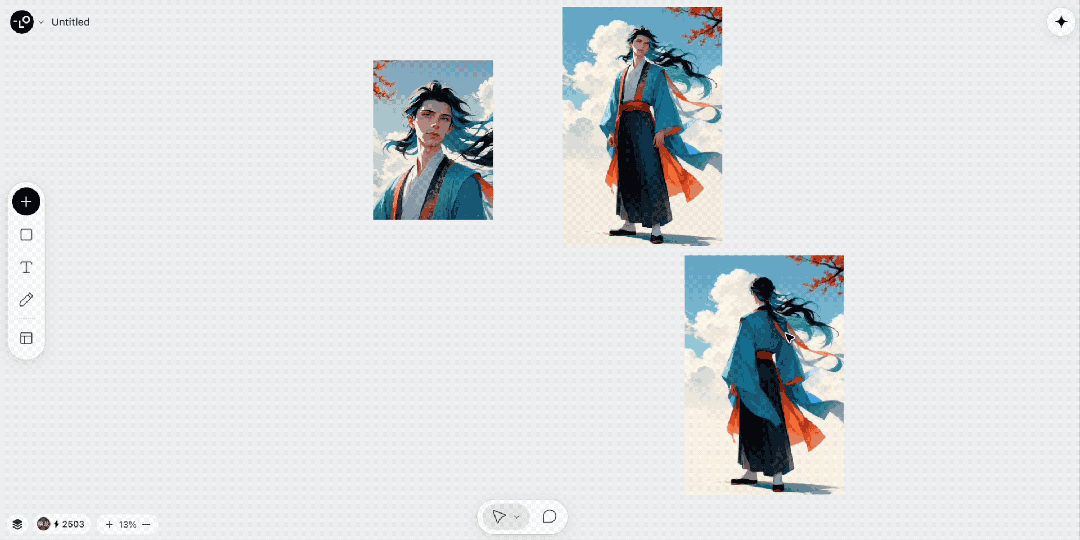
人物搞定之后,我们再做一张图,让人走到寺庙的正面。
下面是我的操作过程,在 Lovart 中,画一条线,注明人应该走到寺庙的什么位置,然后输入提示词,就可以开始生成了。这次我用的英文提示词,因为调试了很多次后发现,英文提示词似乎模型更能够理解。
Extract the character (full-body back view) from the left image, remove the original background, and place the character on the ground in the right image scene according to the indicated arrow position. Adjust the character’s scale with reference to the temple in the right image, ensuring the character occupies less than one-third of the frame, proportionally fitting with the architecture and environment. The posture should be natural, with clothing naturally fitting the body and motion appearing realistic. The hair and accessories should hang naturally, consistent with gravity and body movement. Ensure the character fully blends into the new environment in terms of lighting, perspective, and color tone, so the character looks as though they originally belonged to the scene, avoiding any stiff or layered effect. The overall composition should be smooth, with the character and environment appearing unified and realistic. Do not alter any other elements of the right image.

现在就可以做第一段视频了。生成视频我还是用的可灵的模型,虽然 Veo3 也可以,但测试下来,我觉得还是可灵的效果好一点。
我的提示词是:
镜头跟随男性背影人物移动,画面稳定,人物从前景自然向前行走,一直走进寺庙,跨进寺庙门槛即可,步伐流畅均匀、有节奏,走姿自然,手臂随步伐轻微摆动,符合男性正常走路速度。遇到台阶时两级两级上台阶,动作自然衔接,身体重心过渡合理,上台阶姿态真实流畅,不僵硬也不漂浮。人物动作连续稳定,场景清晰无抖动,镜头平滑跟随人物前进。人物走上台阶后画面定格,同时表现男性继续跨入寺庙,动作自然衔接,不需继续跟随镜头深入寺庙内部。寺庙内部保持完全漆黑,不生成任何物体或其他颜色。

除了 Veo3 和可灵之外,Lovart 还集成了 Hailuo、Vidu 等等其他视频生成模型,根据自己的喜好选择就行。
下面是第一段完稿的视频:
该视频属于AI生成
人物走进寺庙后,我想展示它和整个空间的互动。
电影中的寺庙源自山西的永安禅寺,而永安禅寺内,最出名的是壁画。没看电影之前我也不知道这些,后来上小红书一查,才知道,这个壁画真的很震撼:撕开愤怒面露出慈悲容。我们接下来,试试让人物和这些壁画交流。
我在小红书上找了一张永安禅寺内部空间的图片。继续开始生成,过程和刚才差不多,找参考图片,给提示词:
生成左图寺庙的内部场景,确保画面明确表现为寺庙室内空间氛围。内部布局严格参考右图壁画,保持壁画风格和图案一致,壁画清晰可见。寺庙内部空间、壁画与地面,画面通透自然。整体空间呈现破旧氛围,墙面、柱子、地面带有裂纹、斑驳、剥落、磨损、风化痕迹,破损真实自然,符合传统寺庙建筑与艺术品年久失修的逻辑。地面为石砖/地砖材质,呈现自然风化与破损效果。光照主要由寺庙外的阳光斜射进入室内,整体氛围偏灰暗,仅有极轻微、柔和的漏光,不要过强或夸张,保证壁画完整可见。光影柔和自然,氛围古朴沉稳,二次元清晰线条,赛璐璐上色,柔和低饱和色彩,细节丰富,突出独特的二次元破旧美感。

但这次,生成得并不顺利。恰好,我给大家分享下怎么在 Lovart 中调图。Lovart 有很多种修改图片的方法,我的经验是,想对局部微调的时候,最好还是用右侧的对话框。

经过大概半小时的调整后,终于大功告成。下面是我的成片,光影的效果,壁画的呈现,都符合我的预期。氛围感拉满了。
紧接着,我继续生成两张人物在空间中的照片:一个近景,一个远景。
最后,我再把人物素材拼接成一个在空间中行走的视频。不过这次拼接我用的是 MiniMax 的模型,可灵这次的表现没那么理想。
这也是 Lovart 最爽的地方:想换模型时完全不需要反复上传图片,所有内容和上下文都能在同一块画布里无缝衔接,创作流程不会被打断。
最终,我把所有片段全部导入到剪映,简单剪辑,加上配音,就形成了现在的作品。这已经完全超出我预期了,特别是下面这段:
#04
写在最后
其实在 Nano Banana 发布的时候,我就曾经有过今天这支视频的构想。
但无奈,当时测了几次效果都不理想。这次,Seedream 4.0 带来了全新的可能。
模型之间很难说谁更强,各有擅长,我们要做的,是在合适的地方用合适的模型。
Lovart 给我的感觉,更像是一块把各种模型整合起来的工作台。
它不是只依赖某一个模型,而是把不同模型当成可以互相搭配的工具,让我们可以在同一个环境里反复试错、替换、组合。
做角色设计时,我们会用 Seedream 4.0,需要更写实的细节就切回 Nano Banana,做镜头衔接时,再用上可灵或 Veo3。
所有这些尝试都发生在同一块画布上,不需要重新上传素材、重新熟悉平台流程,也不会打断思路。
我觉得最大的变化是:
创作不再是反复试探模型能做到什么,而是回到「我想做什么」这件事本身。
当工具不再成为障碍,创意才真正开始生长。








